
In the previous blog post I described how to catch errors early at the cost of somewhat increased compile times. In this one, I’ll explore the other direction and discuss reducing compile times, again using the fmt library as an example.
Use variadic templates judiciously
Variadic templates are awesome, they enable natural function-style APIs where we previously had to get by with, often confusing, operator overload. For example, compare
fmt::print("The answer is {}.", 42);
to
std::cout << boost::format("The answer is %1%.") % 42;
Can you even tell from the top of your head which operator, % or <<, has
higher precedence?
However, uncontrolled use of variadic templates can be a compile performance killer. One of the first design choices in the fmt library was to limit the use of variadic templates to the top-level API. This is achieved by a kind of a type erasure where an argument pack is converted into an array of variants.
// Not parameterized on formatting arguments.
std::string vformat(string_view format_str, format_args args);
template <typename... Args>
inline std::string format(string_view format_str, const Args&... args) {
// make_args constructs an array of variants which is passed to vformat.
return vformat(format_str, make_args(args...));
}
This makes the code much faster to compile and reduces the code bloat at the
minor cost of a dispatch on an argument type at runtime. This cost is negligible
compared to the actual formatting and parsing, and fmt can still easily beat
glibc’s
printf.
To illustrate the effects of this technique, let’s compare fmt to Folly Format, which wires variadic templates throughout the formatting code, on a test that compiles and links 100 translation units each having a few formatting function calls.
As you can see, this gives us ~4x better compile times (although variadic template instantiation is not the only factor here) and we’ll see if it’s possible to improve even more using other methods.
Avoid recursive template instantiation
This is related to previous item because variadic templates are often used together with recursion. In some cases it is possible to avoid recursion, for example, in version 3.0 of fmt recursive templates where replaced with array initialization (thanks to Dean Moldovan), along the lines of
variant data[] = {make_variant(args)...};
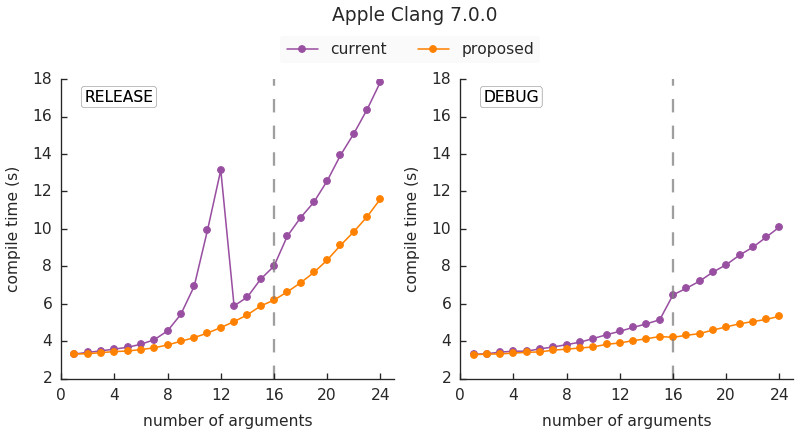
This gave a big improvement in compile times, especially for large number of arguments:
Balance the work done at compile and run time
No work is less work than some work.
– Andrei Alexandrescu
Doing less work at compile time seems like an obvioius thing and it’s not
specific to C++ or AOT compilation for that matter. For example, as I reported
before, formatting in Julia is spectacularly bad,
because they unsuccessfully try to generate “optimal” code for each formatting function
(actually macro) call which results in enormous bloat and still performs worse
than sprintf that does everything at runtime. Add to this a slow JIT
and interactive environment being Julia’s main use case and you’ll get the
picture. The lesson that we can learn from it is that there should be a
balance between the work done at compile (JIT or AOT) and run time.
Is formatting a bottleneck in your application and if it is, does it make sense
to try optimizing all the calls or just the ones that actually matter?
The goal of reducing compile times seems to go against improving safety with
compile-time checks. Fortunatley, in this case we can have our cake and eat
it too because we can already fall back to runtime checks if a compiler doesn’t
have proper constexpr support. So we can develop with compile-time checks
disabled and enjoy fast compile times and have them enabled in continuous
integration and be notified about any errors asynchronously as it is often done
with tests.
And if formatting is really a bottleneck in some part of your application, you can use the Write API and have faster formatting at the cost of longer compilation and more generated code just for the translation units / call sites where performance is critical.
Optimize dependencies
There are a few things that can be done to optimize compile-time dependencies:
Remove unused includes. This seems trivial but I saw numerous cases during code reviews where people refactored code and forgot to remove includes that are no longer used. Ideally this is something that should be automated (let me know in the comments if you know a tool for that).
Prefer non-header-only mode, to quote Sean Middleditch:
“Header only” is an anti-feature. Fast compiles are important. PCHes only fix a fraction of the problems of header bloat. Avoiding 15 minutes of setup to get a library building/precompiled in exchange for months of lost productivity waiting for slow builds is a pretty bad trade off.
Some libraries, fmt included, provide an opt-in header-only mode. While it seems like an easy way to use a library, header-only feature will cost you dearly in terms of compile times, so I highly recommend building the library instead and using the default non-header-only interface. In case of fmt, you just need to add a few source files (one file,
format.cc, for the core library) to your project or add fmtlib as a subdirectory in CMake.Modern build systems such as CMake make it super easy to use third-party libraries (at least open-source ones) and most popular projects already have CMake build config. I personally contributed one to the GNU Scientific Library.
Consider using the pimpl idiom to decouple interface from the implementation.
Also make sure that you optimize for the common use case. For example, the next
major version of the fmt library (currently the std
branch) will have a
lightweight header file fmt/core.h that provides the core formatting API that
should cover most use cases. It is just 674 significant LoC and includes 4
standard library headers with <string> being the heaviest.
Results
Here are the most resent compile time benchmark results using Apple LLVM version 9.0.0 (clang-900.0.39.2) on OS X, optimized mode:
With the techniques described above, the compile time of the benchmark project
using the std branch of fmt has been reduced to 22 seconds or just 220
milliseconds per translation unit. printf is still much faster, but large
portion of compile times are contributed just by including <string> as
shown by the printf+string line in the benchmark where formatting is still
done by printf but we add an extra unused <string> include. This suggests
that if modules reduce #include overhead, we’ll be able to bridge the gap between
fmt and stdio and, more generally, between compile-time responsible C++ projects
and their C counterparts.
Note that this benchmark doesn’t use ccache, parallel builds or precompiled headers so in reality compile times will be much lower.
Last modified on 2017-12-09